redis数据结构
dio 2020-07-22 redis
# 一、Redis知识系统观
Redis从应用维度有:缓存使用、集群运用、数据结构的巧妙使用;
Redis从系统维度有:可以归类为三高
- 高性能:线程模型、网络 IO 模型、数据结构、持久化机制;
- 高可用:主从复制、哨兵集群;
- 高拓展:Cluster 分片集群
Redis 为了高性能,从各方各面都进行了优化。
基准测试:横轴是连接数,纵轴是 QPS
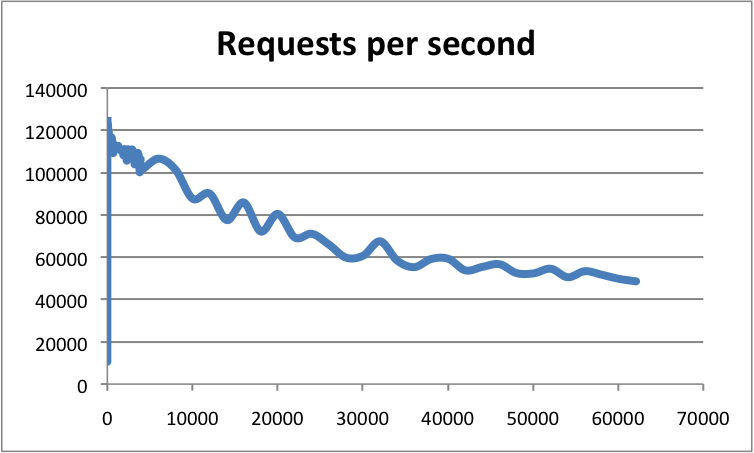
# 二、Redis为什么这么快?
- Redis是基于内存操作,需要的时候需要我们手动持久化到硬盘中
- Redis高效数据结构,对数据的操作也比较简单
- Redis是单线程模型,从而避开了多线程中上下文频繁切换的操作
- 使用多路I/O复用模型,非阻塞I/O
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
# 1.1、基于内存的操作实现
Redis 是基于内存的数据库,不论读写操作都是在内存上完成的,完全吊打磁盘数据库的速度。Redis之所以可以使用单线程来处理,其中的一个原因是,内存操作对资源损耗较小,保证了处理的高效性。
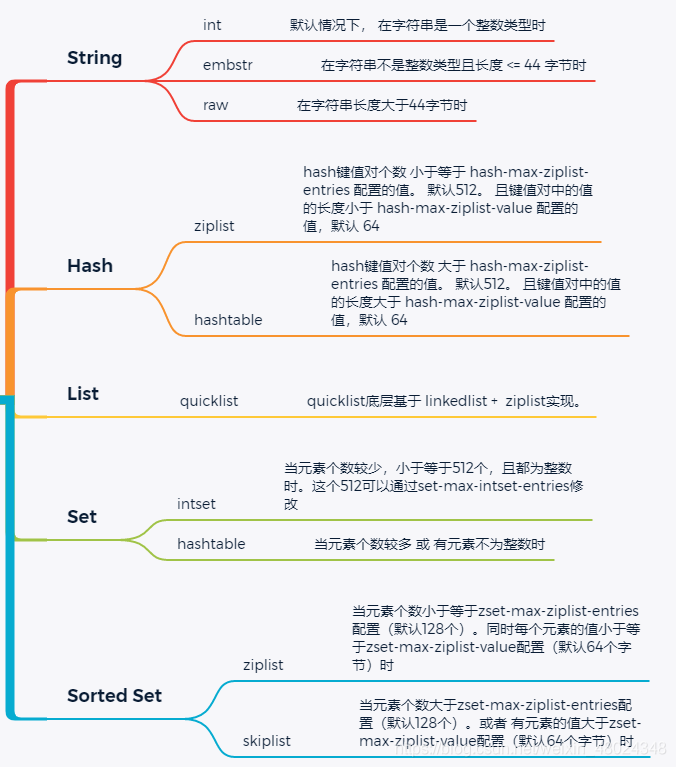
# 1.2、高效的数据结构
string字符串对象
//简单动态字符串结构体
struct sdshdr {
// 字符串长度
int len;
// buf数组中未使用的字节数
int free;
// 字节数组,用于保存字符串
char buf[];
};
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
hash对象
- 哈希对象的编码可以是ziplist或者hashtable。
如果此时使用ziplist编码,那么该Hash对象在内存中的结构如下:
//Redis使用的哈希表由dictht结构定义:
typedef struct dictht{
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size-1
unsigned long sizemask;
// 该哈希表已有节点数量
unsigned long used;
} **dictht**
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- Hash对象在内存中的结构如下:
- 对象指针指向dict字典 : ht是大小为2,且每个元素都指向dictht哈希表。一般情况下,字典只会使用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进行rehash时使用。rehashidx记录了rehash的进度,如果目前没有进行rehash,值为-1。
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
//rehash索引
// 当rehash不在进行时,值为-1
int rehashidx;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 字典使用dictht hash表
- table属性是一个数组,数组中的每个元素都是一个指向dictEntry结构的指针,每个dictEntry结构保存着一个键值对。size属性记录了哈希表的大小,即table数组的大小。used属性记录了哈希表目前已有节点数量。sizemask总是等于size-1,这个值主要用于数组索引。
typedef struct dictht{
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size-1
unsigned long sizemask;
// 该哈希表已有节点数量
unsigned long used;
} dictht
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
- 哈希表节点使用dictEntry结构表示,每个dictEntry结构都保存着一个键值对
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
unit64_t u64;
nit64_t s64;
} v;
// 指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
ziplist压缩列表
跳跃表skiplist
是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
# 1.3、单线程模型
我们要明确的是:Redis 的单线程指的是 Redis 的网络 IO 以及键值对指令读写是由一个线程来执行的。 对于 Redis 的持久化、集群数据同步、异步删除等都是其他线程执行。
- 单线程是否没有充分利用 CPU 资源呢?
官方答案:因为 Redis 是基于内存的操作,使用Redis时,几乎不存在CPU成为瓶颈的情况, Redis主要受限于服务器内存和网络。例如在一个普通的Linux系统上,Redis通过使用pipelining每秒可以处理10万个请求,所以如果应用程序主要使用O(N)或O(log(N))的命令,它几乎不会占用太多CPU。既然单线程容易实现,而且 CPU 不会成为瓶颈,那就顺理成章地采用单线程的方案了。
- IO多路复用模型和性能优良的事件驱动
Redis 采用 I/O 多路复用技术,并发处理连接。采用了 epoll + 自己实现的简单的事件框架。epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,绝不在 IO 上浪费一点时间。

# 三、Redis 唯快不破的原理总结
- 纯内存操作:一般都是简单的存取操作,线程占用的时间很少,时间的花费主要集中在 IO 上,所以读取速度快。
- 采用单线程模型:保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
- Redis 使用IO多路复用模型:非阻塞 IO,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,Redis 采用自己实现的事件分离器,效率比较高。
- Redis高效数据结构,对数据的操作也比较简单:
- (1)整个 Redis 就是一个全局哈希表:他的时间复杂度是 O(1),而且为了防止哈希冲突导致链表过长,Redis 会执行 rehash 操作,扩充 哈希桶数量,减少哈希冲突。并且防止一次性重新映射数据过大导致线程阻塞,采用 渐进式 rehash。巧妙的将一次性拷贝分摊到多次请求过程后总,避免阻塞。
- (2)Redis 全程使用 hash 结构:读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。可以根据实际存储的数据类型选择不同编码。