es深度分页问题
# 深度分页会有什么问题
ElasticSearch普通分页查询时通过from+size这两个参数实现,类似于MySQL的limit 分页
from:表示当前页码
size:表示每页展示条数 例子:
#普通分页查询查询
GET index_user_latest/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
2
3
4
5
6
7
8
9
普通分页优缺点:
1.优点:通用,可以指定页码和每页条数
2.缺点:有深度分页的问题
深度分页的问题,参考官方文档
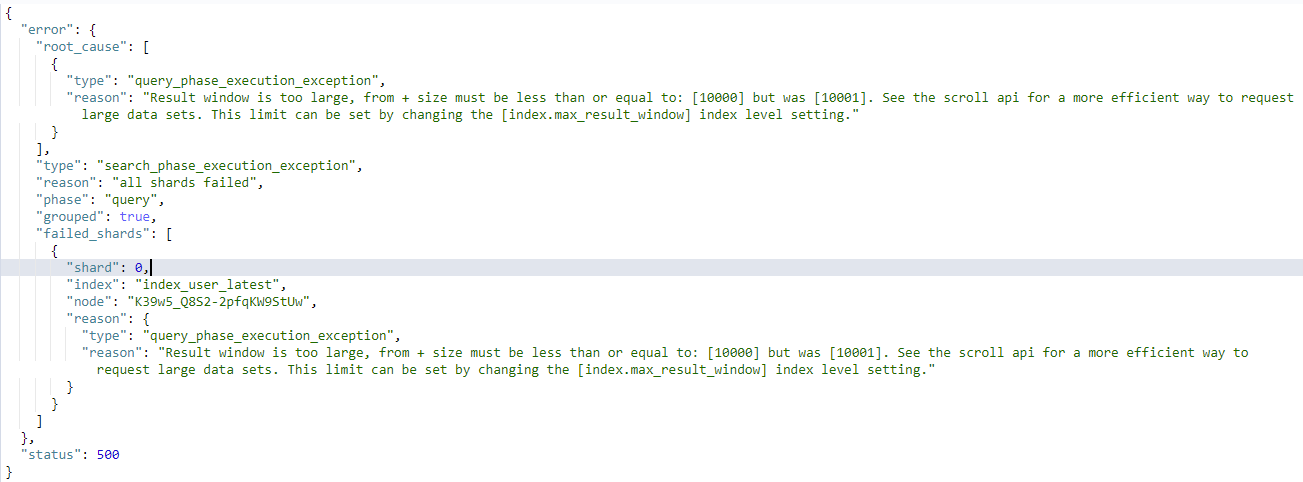
1 原文:By default, you cannot page through more than 10,000 hits using the from and size parameters. To page through more hits, use the search_after parameter.
2 翻译:默认情况下,不能通过from+size分页查询到超过10000条数据,如果要查询到10000条以及更多的数据,可以使用search_after这个参数
GET index_user_latest/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 100001
}
2
3
4
5
6
7
8
GET index_user_latest/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 100001
}
2
3
4
5
6
7
8
以上两种情况都会导致以下查询错误的情况
# 解决方案
深度分页的解决方案主要有以下几种
1.(不推荐)max_result_window
该参数可以调整ElasticSearch分页查询的最大结果窗口参数:
该参数默认情况下是:10000,可以通过修改settings参数来调大,缺点是修改参数不能本质上解决深度分页问题,反而会给ES各个shard更大的数据查询压力
2.search_after 特点,查询的是ES实时的数据(相对于Scrooll而言),可以一直进行下一页查询,因此这种方案适合于客户端场景的没有页码的查询,例如推荐刷新等等
缺点:,只能查询下一页,不能上翻页
注意:
1.search_after 查询时from参数必须指定为0或-1,或者直接不指定
2.search_after 需要指定一个唯一的排序字段,通常可以是文档的主键_id字段,同时也可以指定其他的多个字段
示例
GET index_user_latest/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 1
,
"sort": [
{
"dbId": {
"order": "desc"
}
}20 ]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
查询结果
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 596127,
"max_score" : null,
"hits" : [
{
"_index" : "index_user",
"_type" : "t_user",
"_id" : "154393210",
"_score" : null,
"_source" : {
//省略
},
"sort" : [
18970447
]
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
这里可以使用sort返回的字段作为search_after查询的开始,如下
GET index_user_latest/_search
{
"query": {
"match_all": {}
},
"search_after":[18970447],
"size": 1
,
"sort": [
{
"dbId": {
"order": "desc"
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
3.scroll 查询
参考官方文档 https://www.elastic.co/guide/en/elasticsearch/reference/current/scroll-api.html scroll 查询特点是滚动查询,会在当前生成本次查询的快照版本,无法查询到最新的数据
首次使用srcoll
会返回一个scroll_id,下次查询的时候携带该scroll_id进行查询
第二次查询 带上上一次的
注意,scroll 可以使用当前查询快照的过期时间,如果超过当前的过期时间,则查询会报错
注意:使用完成后,可以手动清除当前scoll快照,释放内存