kafak问题解答
如果消费者数超过分区数会怎么样?(顺丰 滴滴) 怎么保证数据的可靠投递?(陌陌 字节) 消费者的 offset 存在哪里?(字节 腾讯 陌陌) 如何通过 offset 定位消息?(字节) 时间轮的原理(陌陌 顺丰) kafka 写入高性能的原因,sendfile 和 mmap 原理,为什么不用 splice(滴滴)
# 1 Kafka单条日志传输大小
Kafka对于消息体的大小默认为单条最大值是1M但是在我们应用场景中,常常会出现一条消息大于1M,如果不对Kafka进行配置。则会出现生产者无法将消息推送到Kafka或消费者无法去消费Kafka里面的数据,这时我们就要对Kafka进行以下配置:server.properties replica.fetch.max.bytes: 1048576 broker可复制的消息的最大字节数, 默认为1M message.max.bytes: 1000012 kafka 会接收单个消息size的最大限制, 默认为1M左右 注意:message.max.bytes必须小于等于``replica.fetch.max.bytes,否则就会导致replica之间数据同步失败。
# 5 Kafka分区分配策略
在 Kafka内部存在两种默认的分区分配策略:Range和 RoundRobin。 Range是默认策略。Range是对每个Topic而言的(即一个Topic一个Topic分),首先对同一个Topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。 然后用Partitions分区的个数除以消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。 例如:我们有10个分区,两个消费者(C1,C2),3个消费者线程,10 / 3 = 3而且除不尽。 C1-0 将消费 0, 1, 2, 3 分区 C2-0 将消费 4, 5, 6 分区 C2-1 将消费 7, 8, 9 分区 第一步:将所有主题分区组成TopicAndPartition列表,然后对TopicAndPartition列表按照hashCode进行排序,最后按照轮询的方式发给每一个消费线程。
# kafka存储结构
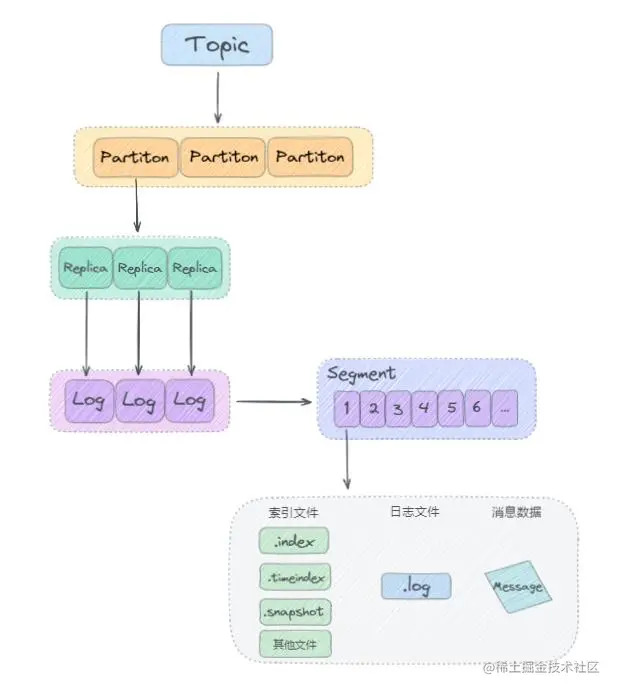
- Kafka 最终的存储实现方案, 即**基于顺序追加写日志 + 稀疏哈希索引。
- Kafka 是基于「主题 + 分区 + 副本 + 分段 + 索引」的结构
1. kafka 中消息是以主题 Topic 为基本单位进行归类的,这里的 Topic 是逻辑上的概念,实际上在磁盘存储是根据分区 Partition 存储的, 即每个 Topic 被分成多个 Partition,分区 Partition 的数量可以在主题 Topic 创建的时候进行指定。
2.Partition 分区主要是为了解决 Kafka 存储的水平扩展问题而设计的, 如果一个 Topic 的所有消息都只存储到一个 Kafka Broker上的话, 对于 Kafka 每秒写入几百万消息的高并发系统来说,这个 Broker 肯定会出现瓶颈, 故障时候不好进行恢复,所以 Kafka 将 Topic 的消息划分成多个 Partition, 然后均衡的分布到整个 Kafka Broker 集群中。
3. Partition 分区内每条消息都会被分配一个唯一的消息 id,即我们通常所说的 偏移量 Offset, 因此 kafka 只能保证每个分区内部有序性,并不能保证全局有序性。
4. 然后每个 Partition 分区又被划分成了多个 LogSegment,这是为了防止 Log 日志过大,Kafka 又引入了日志分段(LogSegment)的概念,将 Log 切分为多个 LogSegement,相当于一个巨型文件被平均分割为一些相对较小的文件,这样也便于消息的查找、维护和清理。这样在做历史数据清理的时候,直接删除旧的 LogSegement 文件就可以了。
5. Log 日志在物理上只是以文件夹的形式存储,而每个 LogSegement 对应磁盘上的一个日志文件和两个索引文件,以及可能的其他文件(比如以".snapshot"为后缀的快照索引文件等)
# 消息可靠性传输,是非常重要,消息如果丢失,可能带来严重后果
producer端: 不采用oneway发送,使用同步或者异步方式发送,做好重试,但是重试的Message key必须唯一 投递的日志需要保存,关键字段,投递时间、投递状态、重试次数、请求体、响应体
broker端: 多主多从架构,需要多机房 同步双写、异步刷盘 (同步刷盘则可靠性更高,但是性能差点,根据业务选择) 机器断电重启:异步刷盘,消息丢失;同步刷盘消息不丢失 硬件故障:可能存在丢失,看队列架构
consumer端 消息队列一般都提供的ack机制,发送者为了保证消息肯定消费成功,只有消费者明确表示消费成功,队列才会认为消息消费成功,中途断电、抛出异常等都不会认为成功——即都会重新投递,每次在确保处理完这个消息之后,在代码里调用ack,告诉消息队列消费成功 消费端务必做好幂等性处理 消息消费务必保留日志,即消息的元数据和消息体
# 消费者的 offset 存在哪里
kafka0.9版本之前,consumer默认将offset保存在zookeeper中,从0.9版本开始,consumer默认将offset保存在kafka一个内置的topic中,该topic为_consumer_offsers.
# 如何通过 offset 定位消息
索引文件中的元数据指向对应数据文件中Message的物理偏移地址。
# 时间轮循
Kafka 使用 kafka.server 包下的 DelayedOperationPurgatory(下文简称 purgatory)类来管理异步任务(即延时操作 DelayedOperation)。每次 Kafka 收到一个请求,都会启动一个异步任务,如果不能立刻完成(比如 acks 设为 all 的 Produce 请求),则扔给 purgatory 保存(即插入到内部的时间轮中)。
# kafka 写入高性能的原因,sendfile 和 mmap 原理,为什么不用 splice
1.顺序写入磁盘,增加IO性能
2.页缓存pageCache
3.零拷贝
4.网络数据采用压缩算法
零拷贝 sendfile(in,out) 数据直接在内核完成输入和输出,不需要拷贝到用户空间再写出去。 kafka数据写入磁盘前,数据先写到进程的内存空间。
mmap文件映射 虚拟映射只支持文件; 在进程 的非堆内存开辟一块内存空间,和OS内核空间的一块内存进行映射, kafka数据写入、是写入这块内存空间,但实际这块内存和OS内核内存有映射,也就是相当于写在内核内存空间了,且这块内核空间、内核直接能够访问到,直接落入磁盘。
splice 依赖关系影响,后续sendfile升级就是基于splice升级的